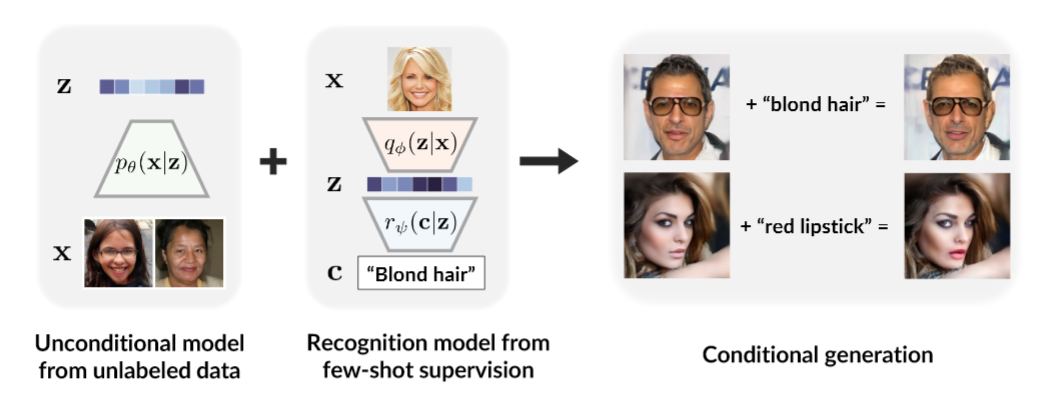
Conditioning on few-shot labels
We can learn information about a label from a few examples (e.g. 100 faces with blond hair), and D2C can generate new images with that label (faces with blond hair).

Conditional generative models of high-dimensional images have many applications, but supervision signals from conditions to images can be expensive to acquire. This paper describes Diffusion-Decoding models with Contrastive representations (D2C), a paradigm for training unconditional variational autoencoders (VAEs) for few-shot conditional image generation.
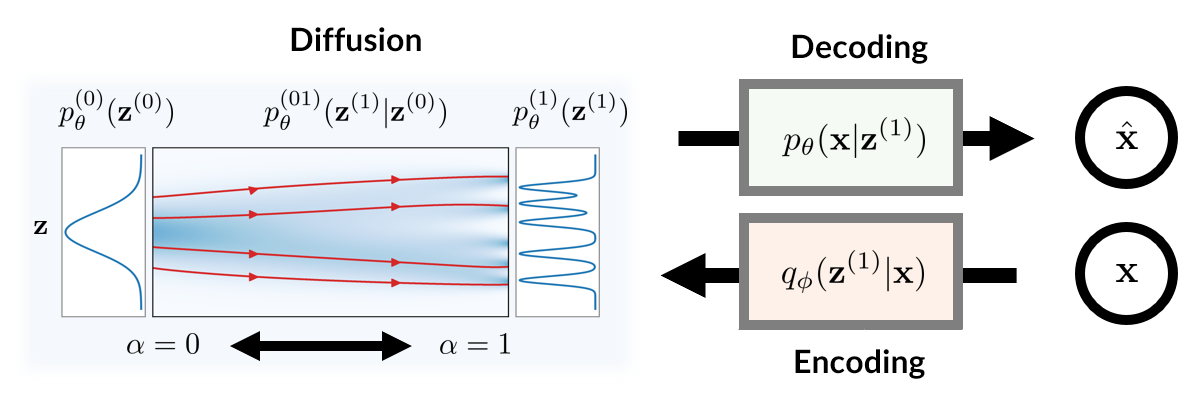
D2C uses a learned diffusion-based prior over the latent representations to improve generation and contrastive self-supervised learning to improve representation quality. D2C can adapt to novel generation tasks conditioned on labels or manipulation constraints, by learning from as few as 100 labeled examples. On conditional generation from new labels, D2C achieves superior performance over state-of-the-art VAEs and diffusion models. On conditional image manipulation, D2C generations are two orders of magnitude faster to produce over StyleGAN2 ones and are preferred by 50% - 60% of the human evaluators in a double-blind study.
We can learn information about a label from a few examples (e.g. 100 faces with blond hair), and D2C can generate new images with that label (faces with blond hair).
We can also levearge learned labels to manipulate images, such as adding a red lipstick or a beard to a human face while keeping other features similar.

For more blond results, please visit here.
| Name | Original | D2C | StyleGAN2 | NVAE | DDIM |
|---|---|---|---|---|---|
| 0 |
 |
 |
 |
 |
 |
| 1 |
 |
 |
 |
 |
 |
| 2 |
 |
 |
 |
 |
 |
| 3 |
 |
 |
 |
 |
 |
| 4 |
 |
 |
 |
 |
 |
| 5 |
 |
 |
 |
 |
 |
| 6 |
 |
 |
 |
 |
 |
| 7 |
 |
 |
 |
 |
 |
| 8 |
 |
 |
 |
 |
 |
| 9 |
 |
 |
 |
 |
 |
For more red lipstick results, please visit here.
| Name | Original | D2C | StyleGAN2 | NVAE | DDIM |
|---|---|---|---|---|---|
| 0 |
 |
 |
 |
 |
 |
| 1 |
 |
 |
 |
 |
 |
| 2 |
 |
 |
 |
 |
 |
| 3 |
 |
 |
 |
 |
 |
| 4 |
 |
 |
 |
 |
 |
| 5 |
 |
 |
 |
 |
 |
| 6 |
 |
 |
 |
 |
 |
| 7 |
 |
 |
 |
 |
 |
| 8 |
 |
 |
 |
 |
 |
| 9 |
 |
 |
 |
 |
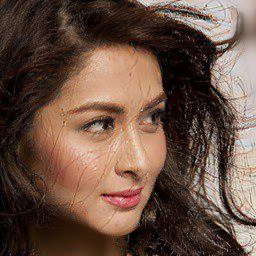 |
For more beard results, please visit here.
| Name | Original | D2C | StyleGAN2 | NVAE | DDIM |
|---|---|---|---|---|---|
| 0 |
 |
 |
 |
 |
 |
| 1 |
 |
 |
 |
 |
 |
| 2 |
 |
 |
 |
 |
 |
| 3 |
 |
 |
 |
 |
 |
| 4 |
 |
 |
 |
 |
 |
| 5 |
 |
 |
 |
 |
 |
| 6 |
 |
 |
 |
 |
 |
| 7 |
 |
 |
 |
 |
 |
| 8 |
 |
 |
 |
 |
 |
| 9 |
 |
 |
 |
 |
 |
@article{sinha2021d2c
author = {Sinha*, Abhishek and Song*, Jiaming and Meng, Chenlin and Ermon, Stefano},
title = {D2C: Diffusion-Denoising Models for Few-shot Conditional Generation},
journal = {arXiv preprint arXiv:2106.06819},
year = {2021},
}Our works builds on diffusion generative models (or score-based generative models). Here is a non-exhaustive list. [Song et al., 2019] introduced the idea of generative modeling based on gradients of the log-probability (scores) and Langevin dynamics between data distributions with various levels of noise. [Ho et al., 2020] used a variational approach to determine the schedule for Langevin-like dynamics, and the variational approach was introduced much earlier in [Sohl-Dickstein et al., 2015]. The sampling procedure is interpreted as discretization of an SDE [Song et al., 2021a] and can be accelerated by using an ODE point of view [Song et al., 2021b].
Despite the success in image synthesis, diffusion models have not demonstrated sound results in terms of latent variable inference, which can be important if we wish to imbue them with conditions learned from few-shot. The ODE approach can be used to obtain latent variables, but they are "fixed" in some sense (determined by the scores at different noise levels), and cannot be integrated with recent advances in contrastive self-supervised learning. This motivates our work of integrating diffusion models, VAEs and contrastive learning. A concurrent work demonstrates that VAE + diffusion models in the latent space can achieve state-of-the-art unconditional image synthesis with enough resources in training.